

上一篇文章简单介绍了SDN及其应用场景,臆测的成分大些。本文谈谈SDN的基石:openflow。
我们知道,SDN的核心是将control plane(下文统称controller)和data plane(下文统称oSwitch,openflow switch)分离,由一个中央集权的controller(好比一个军团的将领)指挥成百上千的oSwitch(好比千千万万的士兵),共同完成网络中数据的传输。而openflow,as a protocol,是这套体系正常运作的基石。
本文难度稍大,可能不适合没有网络设备基础知识的读者阅读。我会在下节中稍微讲一些基础概念,如果无法理解,则不建议读下去。
如果到这里还没有晕的话,可以继续读下去。
openflow定义了oSwitch端如何协同controller来处理网络中的packets。这包含两个部分:1) oSwitch端packets处理逻辑 2) oSwitch转发依据,即oSwitch和controller之间的protocol。本文重点讨论再oSwitch端,packets是如何处理的。
我们先放着openflow不表,看看网络设备(switch,router,firewall)进行packets处理的共性,如下图所示:
这样做的好处是:
以相对复杂的firewall为例,看看packets实际是如何处理的:
拓扑很简单:
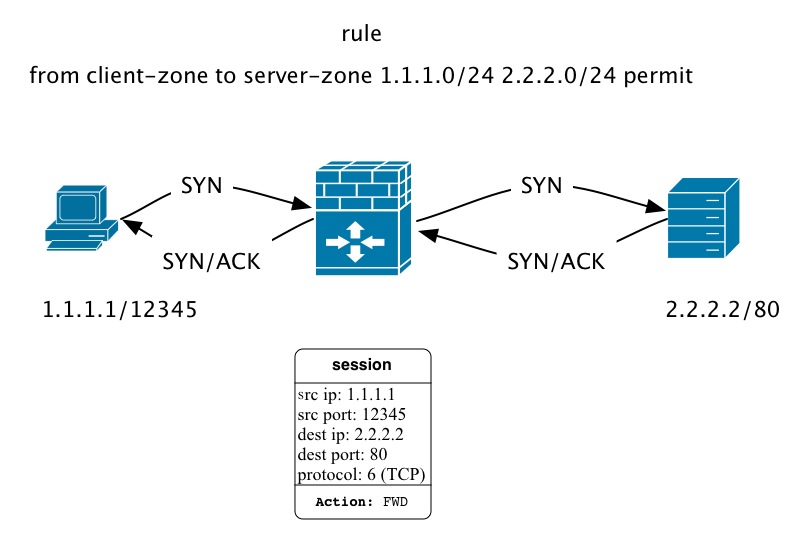
理解了这一思路后,openflow的packets处理方法就很容易明白了。
openflow关心从L1-L4的所有packet header,从这点上看,oSwitch端的很多处理和firewall很像。
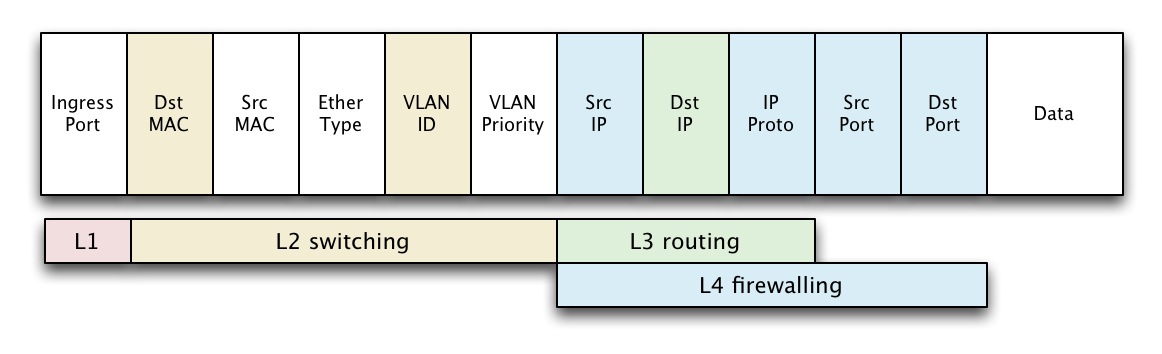
openflow定义了能够match L1-L4 的flow entry:
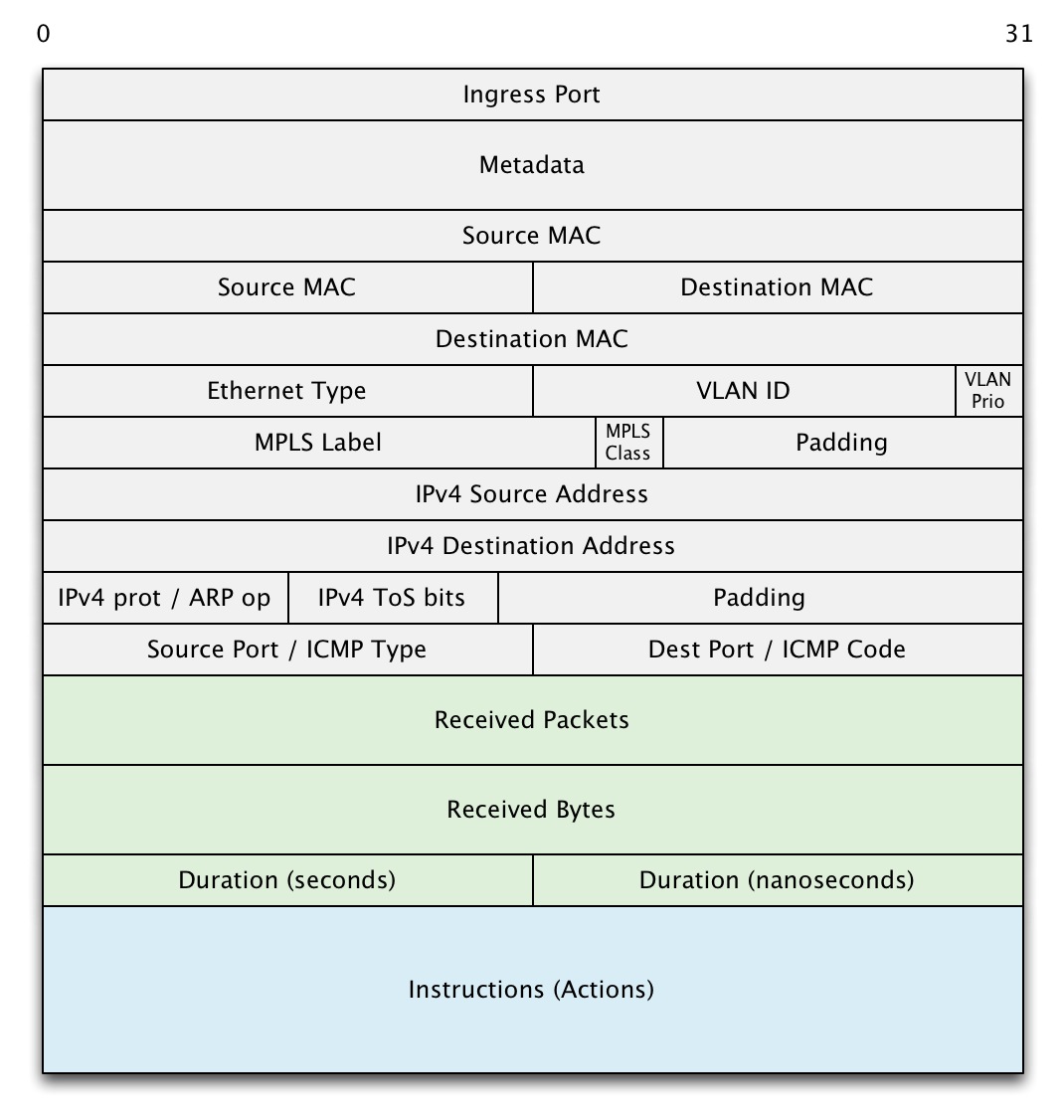
其中,假定instructions使用64bit,那么整个entry大小为76bytes,如果能够支持1M的flow,那么flow table会消耗76M内存。
当packets到达时,openflow是如何match并处理呢?openflow-spec的这张图讲的很明白,我就不多说了:
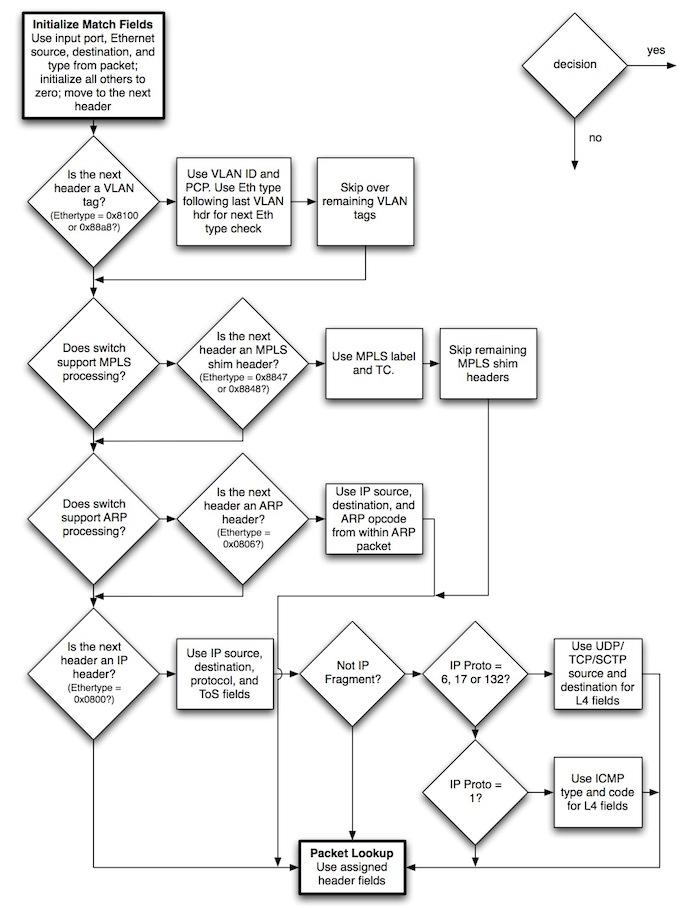
openflow允许系统中存在一到多张flow table并且他们之间以一种pipeline的方式运行。
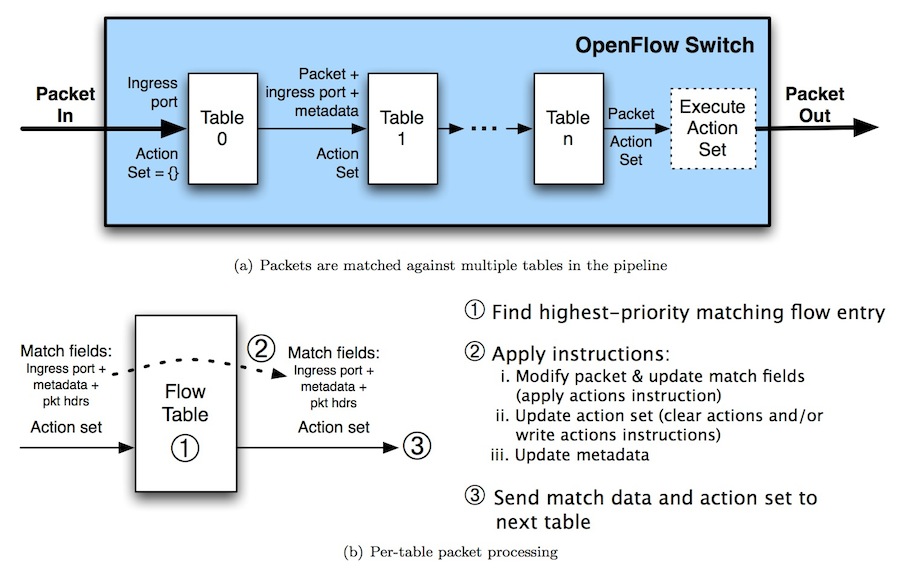
什么情况下一个packet从一张flow table里出来,进入另一张flow table呢?有不少这样的case,我们说一个比较容易理解的。
~假定flow table 1存放IPSec VPN tunnel的flow entry,flow table 2存放普通flow entry。当一个IPSec packet进入flow table 1后match对应的flow entry,其instruction为:1) decryption 2) FWD to flow table 2。当packet被解密,inner ip packet重见天日时,就可以用flow table 2中的flow entry进行转发。~
注:这个理解可能有些错误,因为openflow规定flow table是有序的,但这个VPN in的例子如果换成VPN out的例子则flow table的顺序正好相反,所以和openflow的spec violate...等笔者搞明白些再回过头来修订这个例子Update:
看Open vSwitch时想到一种multi table的模式:即L2,L3,L4各一张table。这说得过去,而且各个flow table是严格有序的。
当packet match到一个flow entry后,要执行对应的instructions,openflow定义了如下instruction:
单独理解instructions有些困难,请继续往下读。
每个packet都有一个action set,初始时为空,当match flow entry时被修改。如果所有instruction都执行完,且没有后续的Goto-Table instruction时,packet上的action set被执行(这里也有个疑问,set一般是无序的,但action的执行必定有序,执行的先后对结果影响很大,我们姑且认为是顺序执行吧)。所以上述的instruction大部分实在操作packet上的action set,即定义我们如何进一步处理这个packet。
Action的执行按照如下顺序:
具体action的列表和作用请参考openflow-spec的p13-16。
我们举一个简单的例子,你在公司访问google.com(假定IP是203.208.46.200)。你的局域网IP是10.0.0.222,ISP分配给你公司的公网IP是22.22.22.22。对于这样一个很常见的网络访问,openflow需要应用如下actions:
上文详述了openflow的flow table如何定义,如何match和怎样处理packets,完全是data plane的事儿。读者一定有一个疑问,那么flow table是如何install到oSwtich中?
这个问题的答案也是SDN的精华所在。我们知道,传统的网络设备,即使将data plane和control plane完全分离到不同的board上,还是在同一台设备中做决策(control plane)及执行决策(data plane)。flow table的installation是由每台网络设备自行决定。而openflow在这里将control plane完全分隔,在oSwitch/Controller之间运行protocol来传递消息,比如说:
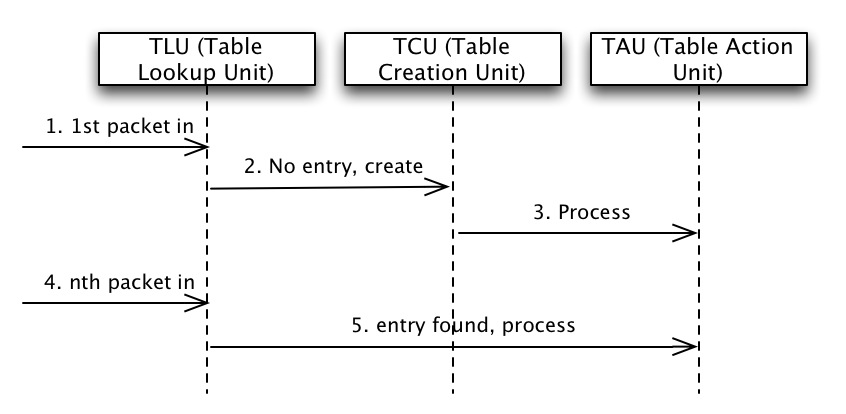
我们用下图来诠释oSwitch和Controller间如何来协作进行packet forwarding:
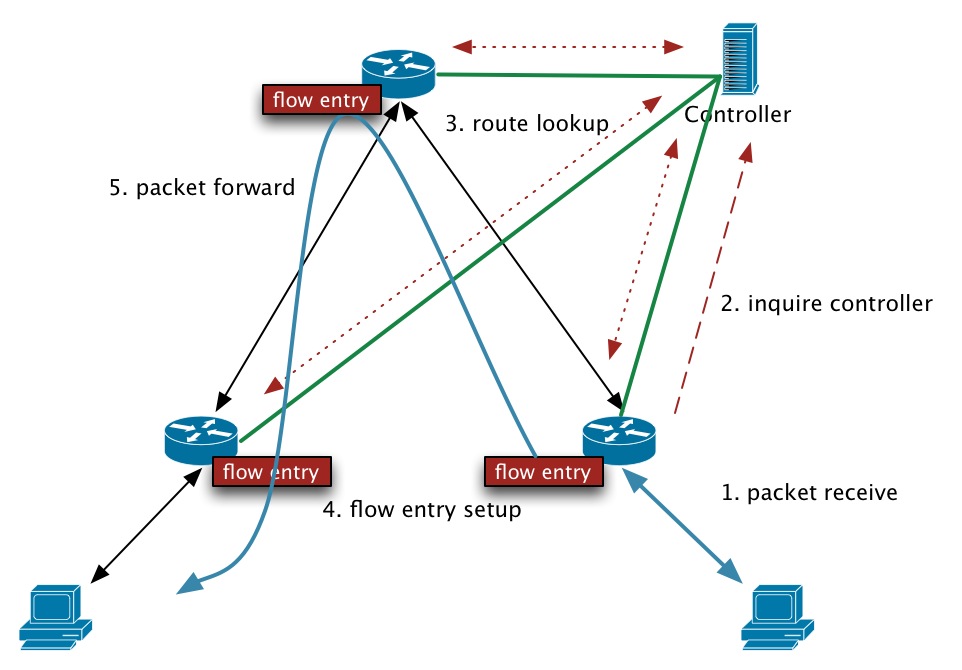
当然,这是很被动的处理方式,first packet的latency会很高。其实也可以采取主动模式,Controller收集到拓扑信息后主动向各个oSwitch发送计算好的flow entries。
具体protocol的细节就不在本文详述,看spec就好了。
[1] open flow spec: http://www.openflow.org/documents/openflow-spec-v1.1.0.pdf
[2] open flow white paper: http://www.openflow.org/documents/openflow-wp-latest.pdf
[1] 这里指LAN主要使用的link layer protocol;WAN不在本文讨论之列
[2] interface更为准确,但这里就不引入新概念了
送上小宝照片一枚。

如果您对本站的文章感兴趣,欢迎订阅我的微博公共账号:程序人生。每次博文发表时,您都能获得通知。此外,公共账号还会不定期推送一些短文,技术心得,供您参考。
