2 Racket语言概要
2.1 Racket语法基础
在Racket的世界里,一切皆为表达式。表达式可以返回一个值,或者一个列表(list)。而函数,则是构成表达式的基本要素。在这一章里,我们深入到Racket的语言细节,看看语言基本的库都提供了哪些必备的功能。
2.1.1 变量绑定
在Racket中,默认情况下,变量的值是不可变的,它只能绑定和重新绑定,如下面的例子:
> (define x 1) > (define x (+ x 1)) > x 2
define 是可以做全局绑定的,每次只能绑定一个变量。如果想一次绑定多个变量,可以使用 let:
> (let ([a 3] [b (list-ref '(1 2 3 4) 3)]) (sqr (+ a b))) 49 > (or a b) ; 这里会抛出undefined异常
let 和 define 最大的不同是 let 是局部绑定,绑定的范围仅仅在其作用域之内,上面的例子中,a 和 b 出了 let 的作用域便不复存在了。
如果在绑定的过程中,需要互相引用,可以使用 let*。我们可以看下面的例子:
> (let* ([x 10] [y (* x x)]) (list x y)) '(10 100)
有时候,你希望一次绑定多个值,可以使用 let-values:
> (let-values ([(x y) (quotient/remainder 10 3)]) (list y x)) '(1 3)
它也有对应的 let*-values 形式。如下例:
> (let*-values ([(pi r rr) (values 3.14159 10 (lambda (x) (* x x)))] [(perimeter area) (values (* 2 pi r) (* pi (rr r)))]) (list area perimeter)) '(314.159 62.8318)
在这个例子里,我们看到 let 也能把一个变量和一个 lambda 函数进行绑定。我们看到,rr 在使用的过程中,需要为其传入一个已经绑定好的变量,比如本例中的 r。那么问题来了,如果函数的参数要延迟到 let 语句的 body 里才能获得,那该怎么办?Racket提供了 letrec:
> (letrec ([is-even? (lambda (n) (or (zero? n) (is-odd? (sub1 n))))] [is-odd? (lambda (n) (and (not (zero? n)) (is-even? (sub1 n))))]) (is-odd? 11)) #t
在介绍它的功能之前,我们先看看同样的例子如果用 let 会有什么后果:
> (let ([is-even? (lambda (n) (or (zero? n) (is-odd? (sub1 n))))] [is-odd? (lambda (n) (and (not (zero? n)) (is-even? (sub1 n))))]) (is-odd? 11)) is-even?: undefined;
cannot reference undefined identifier
这里会提示 is-even? 没有定义。letrec 引入了一个语法层面的概念 locations,这个概念我们 Racket语言进阶 那一章再讲。现在,我们只要这么理解:letrec 会先初始化每个要绑定的变量,为其放上一个占位符,等到引用的时候才真正开始计算。
当然,这种方法并不适用于任何场合:被引用的表达式不能是立即求值的表达式,而是延迟计算的,如上例中的 lambda。几种错误的 letrec 用法:
> (letrec ([x (+ y 10)] [y (+ z 10)] [z 10]) x) y: undefined;
cannot use before initialization
> (letrec ([x (y 10)] [y (z 10)] [z (lambda (a) (+ a 10))]) x) y: undefined;
cannot use before initialization
正确的用法是:
> (letrec ([x (lambda () (+ (y) 10))] [y (lambda () (+ (z) 10))] [z (lambda () 10)]) (x)) 30
如果你不畏艰险,执意要攻克这些语句,那么可以访问 这里 阅读Racket的官方文档。
要完全理解 letrec 并非易事。就目前我们的能力而言,基本的 let 和 let* 在绝大多数场景下都足够用了。Racket还提供了其它一些绑定相关的语句:letrec-values,let-syntax,letrec-syntax,let-syntaxes,letrec-syntaxes,letrec-syntaxes+values。如果你看得头晕目眩,不知所以,那么恭喜你,咱俩感觉一样一样的!我们暂且跳过它们,稍稍休息一下,换换脑子,然后进入下一个环节。
2.1.2 条件语句
注意:这里说条件语句其实是不严谨的,应该是条件表达式。一切皆为表达式,不是吗?
在Racket里,条件语句也是函数。我们看最基本的条件语句:
procedure
(if test-expr true-expr false-expr) → value
test-expr : (判断条件) true-expr : (当条件为真时执行的表达式) false-expr : (当条件为假时执行的表达式)
> (if (positive? -5) (error "doesn't get here") 2) 2 > (if (member 2 (list 1 2 3 4)) 1 (error "doesn't get here")) 1 > (if 'this-is-a-symbol "yes" "no") "yes"
再次强调:判断条件只要不是 #f,任何其它值都等价于 t。
对于其它常见的语言,条件语句可以有多个分支,比如Python里有 elif,使用如下:
if score > 90:
return "A"
elif score > 70:
return "B"
elif score > 60:
return "Pass"
else:
return "Not Pass"Racket的 if 没有多个分支,但是可以通过嵌套来完成相同的功能:
> (define score 55) > (if (> score 90) "A" (if (> score 70) "B" (if (> score 60) "Pass" "Not Pass"))) "Not Pass"
Racket里的 cond 跟其它语言中的 switch 类似,可以类比一下。
当然,同样的功能可以 cond 来完成。cond 的语法如下:
(cond cond-clause ...)
cond-clause = [test-expr then-body ...+] | [else then-body ...+] | [test-expr => proc-expr] | [test-expr]
在 cond 表达式中,每个 test-expr 都按定义的顺序去求值并判断。如果判断结果为 #f,对应的 bodys 会被忽略,下一个 test-expr 会被求值并判断;在这个过程中,只要任何一个计算到的 test-expr 的结果为 #t,其 bodys 就会得到执行,执行的结果作为 cond 整个表达式的返回值。
在 cond 表达式中,最后一个 test-expr 可以被定义为 else。这样,如果前面的判断条件都测试失败,该 test-expr 对应的 bodys 会作为缺省的行为得到执行。
上面的嵌套 if 的写法可以用 cond 表述得更加优雅一些:
> (cond [(> score 90) "A"] [(> score 70) "B"] [(> score 60) "Pass"] [else "Not Pass"]) "Not Pass"
有一种特殊的 test-expr,它可以将自己的结果传递给 proc-expr 作为参数进行处理,定义如下:
[test-expr => proc-expr]
我们看一个例子:
> (cond [(member 2 '(1 2 3 4)) => (lambda (l) (map sqr l))]) '(4 9 16) > (member 2 '(1 2 3 4)) '(2 3 4)
通过这个例子,我们可以感受到条件表达式往往不返回 #t,而尽可能返回一个有意义的值的妙处了。
除了 if 和 cond 这样的标准条件表达式外,由于支持表达式的部分计算,and 和 or 也常常被用做条件表达式的简写。我们看一些例子:
> (and) #t > (and 1) 1 > (and (values 1 2)) 1 2 > (and #f (error "doesn't get here")) #f > (and #t 5) 5 > (or) #f > (or 1) 1 > (or (values 1 2)) 1 2 > (or 5 (error "doesn't get here")) 5 > (or #f 5) 5
对于上面的根据 score 返回成绩评定的条件表达式,可以用 or 这么写:
> (or (and (> score 90) "A") (and (> score 70) "B") (and (> score 60) "Pass") "Not Pass") "Not Pass"
当然,这么写并不简单,读起来不如 cond 的形式舒服。考虑下面的嵌套 if,用 and 表达更漂亮一些:
这个例子的逻辑是,退出编辑器时,如果文件修改了,则弹窗询问用户是否保存,如果用户选择是,则存盘退出,否则都直接退出。
> (if (file-modified? f) (if (confirm-save?) (save-file) #f) #f) > (and (file-modified? f) (confirm-save?) (save-file))
2.1.3 循环与递归
一般而言,函数式编程语言没有循环,只有递归,无论是什么形式的循环,其实都可以通过递归来完成。比如说这样一个循环:
> (for ([i '(1 2 3)]) (display i)) 123
可以这样用递归来实现:
> (define (for/recursive l f) (if (> (length l) 0) (let ([h (car l)] [t (cdr l)]) (f h) (for/recursive t f)) (void))) > (for/recursive '(1 2 3) display) 123
然而,for 这样的循环结构毕竟要简单清晰一些,因此,Racket提供了多种多样的 for 循环语句。我们先看一个例子:
> (for ([i '(1 2 3 4)]) (displayln (sqr i))) 1 4 9 16
一个表达式,如果没有返回值,又没有副作用,那么它存在的必要何在?
注意 for 表达式返回值为 void,并且一般而言,它是有副作用的。for 有很多无副作用的变体,如下所示:
syntax
(for/list (clause ...) body ...+)
syntax
(for/hash (clause ...) body ...+)
syntax
(for/hasheq (clause ...) body ...+)
syntax
(for/hasheqv (clause ...) body ...+)
syntax
(for/vector (clause ...) body ...+)
syntax
(for/flvector (clause ...) body ...+)
syntax
(for/extflvector (clause ...) body ...+)
syntax
(for/and (clause ...) body ...+)
syntax
(for/or (clause ...) body ...+)
syntax
(for/first (clause ...) body ...+)
syntax
(for/last (clause ...) body ...+)
syntax
(for/sum (clause ...) body ...+)
syntax
(for/product (clause ...) body ...+)
syntax
(for*/list (clause ...) body ...+)
syntax
(for*/hash (clause ...) body ...+)
syntax
(for*/hasheq (clause ...) body ...+)
syntax
(for*/hasheqv (clause ...) body ...+)
syntax
(for*/vector (clause ...) body ...+)
syntax
(for*/flvector (clause ...) body ...+)
syntax
(for*/extflvector (clause ...) body ...+)
syntax
(for*/and (clause ...) body ...+)
syntax
(for*/or (clause ...) body ...+)
syntax
(for*/first (clause ...) body ...+)
syntax
(for*/last (clause ...) body ...+)
syntax
(for*/sum (clause ...) body ...+)
syntax
(for*/product (clause ...) body ...+)
我们通过一些例子来具体看看这些循环表达式如何使用:
> (for/list ([i '(1 2 3 4)] [name '("goodbye" "farewell" "so long")]) (format "~a: ~a" i name)) '("1: goodbye" "2: farewell" "3: so long") > (for*/list ([i '(1 2 3 4)] [name '("goodbye" "farewell" "so long")]) (format "~a: ~a" i name)) '("1: goodbye" "1: farewell" "1: so long" "2: goodbye" "2: farewell" "2: so long" "3: goodbye" "3: farewell" "3: so long" "4: goodbye" "4: farewell" "4: so long")
注意看 for*/list 和 for/list 的区别。再看几个例子:
> (for/product ([i '(1 2 3)] [j '(4 5 6)]) (* i j)) 720 > (for/sum ([i '(1 2 3)] [j '(4 5 6)]) (* i j)) 32 > (for/last ([i '(1 2 3)] [j '(4 5 6)]) (* i j)) 18 > (for/hash ([i '(1 2 3)] [j '(4 5 6)]) (values i j)) '#hash((1 . 4) (2 . 5) (3 . 6))
for 循环还有很多内置的函数来获取循环中的值,比如 in-range,in-naturals 等等,如下例所示:
> (for/sum ([i 10]) (sqr i)) 285 > (for/list ([i (in-range 10)]) (sqr i)) '(0 1 4 9 16 25 36 49 64 81) > (for ([i (in-naturals)]) (if (= i 10) (error "too much!") (display i))) 123456789 too much!
我们可以看到,in-naturals 会生成一个无穷的序列,除非在 body 中抛出异常,否则循环无法停止。这个特性可以用于类似其它语言的 while (1) 这样的无限循环。
很多时候,循环不是必须的。Racket是一门函数式编程语言,有很多优秀的用于处理 sequence 的函数,如 map,filter,foldl 等等,当你打算使用 for 循环时,先考虑一下这些函数是否可以使用。
更多有关 for 循环的细节,请参考 Racket官方文档:iterations and comprehensions。
2.2 基本数据结构
了解了最基本的控制结构,我们来看看Racket提供了哪些数据结构。Wirth 说过:
Program = Algorithm + Data Structure |
掌握了一门语言支持的数据结构,你就已经掌握了这门语言的一半的精髓。
2.2.1 数值
数值是Racket的最基本的类型。Racket支持的数值类型非常丰富:整数,浮点数(实数),虚数,有理数(分数)等等。我们看一些例子:
> 1234 1234
> (+ 1000000000000000000000000000000000000000000000000000000000000 4321) 1000000000000000000000000000000000000000000000000000000004321
> 1.4141414141414141 1.4141414141414141
> 1.4141414141414142e+27 1.4141414141414142e+27
> (/ 2 3) 2/3
> (/ 2 3.0) 0.6666666666666666
> 1+2i 1+2i
> (number? 1.4) #t
> (number? (/ 9 10)) #t
> (number? 1+2i) #t
> (number? 1.4e+27) #t
> (exact->inexact 1/3) 0.3333333333333333
> (floor 1.9) 1.0
> (ceiling 1.01) 2.0
> (round 1.5) 2.0
> #b111 7
> #o777 511
> #xdeadbeef 3735928559
最后的三个例子里展示了Racket可以通过 #b,#o,#x 来定义二进制,八进制和十六进制的数字。
2.2.2 string
字符串是基本上所有语言的标配,Racket也不例外。我们看看这些例子:
> (string? "Hello world") #t
> (string #\R #\a #\c #\k #\e #\t) "Racket"
> (make-string 10 #\c) "cccccccccc"
> (string-length "Tyr Chen") 8
> (string-ref "Apple" 3) #\l
> (substring "Less is more" 5 7) "is"
> (string-append "Hello" " " "world!") "Hello world!"
> (string->list "Eternal") '(#\E #\t #\e #\r #\n #\a #\l)
> (list->string '(#\R #\o #\m #\e)) "Rome"
Racket还提供了一个关于 string 的库 racket/string,可以 (require racket/string) 后使用:
> (string-join '["this" "is" "my" "best" "part"]) "this is my best part"
> (string-join '("随身衣物" "充电器" "洗漱用品") "," #:before-first "打包清单:" #:before-last "和" #:after-last "等等。") "打包清单:随身衣物,充电器和洗漱用品等等。"
> (string-split " foo bar baz \r\n\t") '("foo" "bar" "baz")
> (string-split "股票,开盘价,收盘价,最高价,最低价" ",") '("股票" "开盘价" "收盘价" "最高价" "最低价")
> (string-trim " foo bar baz \r\n\t") "foo bar baz"
> (string-replace "股票,开盘价,收盘价,最高价,最低价" "," "\n") "股票\n开盘价\n收盘价\n最高价\n最低价"
> (string-replace "股票,开盘价,收盘价,最高价,最低价" "," "\n" #:all? #f) "股票\n开盘价,收盘价,最高价,最低价"
延伸阅读:更多和 string 相关的函数,可以参考 Strings。
2.2.3 列表
list 是Lisp(LISt Processor)的精髓所在,其重要程度要比 lambda 更胜一筹。其实软件无非是一个处理输入输出的系统:一组输入经过这个系统的若干步骤,变成一组输出。「一组输入」是列表,「若干步骤」是列表,「一组输出」也是列表。所以程序打交道的对象大多是列表。
Lisp里最基本的操作是 car(读/ˈkɑr/) 和 cdr(读/ˈkʌdər/),他们是操作 cons 的原子操作。cons 也被称为pair,包含两个值,car 获取第一个值,cdr 获取第二个值。Racket继承了Lisp的这一特性:
> (cons 'x 'y) '(x . y)
> '(10 . 20) '(10 . 20)
> (define pair (cons 10 20))
> (car pair) 10
> (cdr pair) 20
如果把第二个元素以后的内容看作一个列表,列表也可以被看作是 cons。我们做几个实验:
> (cons 1 (cons 2 3)) '(1 2 . 3)
> (cons 1 (cons 2 (cons 3 '()))) '(1 2 3)
> (cons 1 (cons 2 empty)) '(1 2)
> (list 1 2 3) '(1 2 3)
> (define l1 '(1 2 3 4 5 6 7 8))
> (car l1) 1
> (cdr l1) '(2 3 4 5 6 7 8)
> (car (cdr l1)) 2
> (cadr l1) 2
> (cdr (cdr l1)) '(3 4 5 6 7 8)
> (cddr l1) '(3 4 5 6 7 8)
> (caddr l1) 3
> (cddddr l1) '(5 6 7 8)
在Racket里,pair 不是 list,但 list 是 pair:
> (pair? '(1 . 2)) #t
> (list? '(1 . 2)) #f
> (pair? '(1 2)) #t
> (list? '(1 2)) #t
那么,(cons 1 (cons 2 3)) 代表什么呢?为什么结果这么奇特,不是一个正常的列表?我们暂且放下这么疑问,留待以后再回答这个问题。
我们看看主要的列表操作的函数:
> (define l (list 234 123 68 74 100 1 3 5 8 4 2))
> (first l) 234
> (rest l) '(123 68 74 100 1 3 5 8 4 2)
> (take l 4) '(234 123 68 74)
> (drop l 4) '(100 1 3 5 8 4 2)
> (split-at l 4)
'(234 123 68 74)
'(100 1 3 5 8 4 2)
> (takef l even?) '(234)
> (dropf l even?) '(123 68 74 100 1 3 5 8 4 2)
> (length l) 11
> (list-ref l 0) 234
> (list-tail l 4) '(100 1 3 5 8 4 2)
> (append l '(0 1 2)) '(234 123 68 74 100 1 3 5 8 4 2 0 1 2)
> (reverse l) '(2 4 8 5 3 1 100 74 68 123 234)
> (flatten (list '(1) '(2) '(3))) '(1 2 3)
> (remove-duplicates '(1 2 3 2 4 5 1)) '(1 2 3 4 5)
> (filter (lambda (x) (> x 100)) l) '(234 123)
> (partition (lambda (x) (< x (first l))) l)
'(123 68 74 100 1 3 5 8 4 2)
'(234)
partition 是个有趣的函数,它把列表按照你给定的条件分成两个列表:满足条件的;不满足条件的。嗯,让我们来利用这一函数,写个自己的 quicksort 函数:
> (define l (list 234 123 68 74 100 1 3 5 8 4 2))
> (define (qsort1 l) (if (or (empty? l) (empty? (cdr l))) l (let*-values ([(key) (car l)] [(small big) (partition (lambda (x) (< x key)) (cdr l))]) (append (qsort1 small) (list key) (qsort1 big)))))
> (qsort1 l) '(1 2 3 4 5 8 68 74 100 123 234)
对于给定的列表,我们拿出第一个元素µ,把剩下里的元素分成两份:小于µ的元素列表和大于µ的元素列表。然后对整个过程进行递归,直到所有元素排完。我们虽然实现了 quicksort 的基本功能,但目前只能实现数字的排序,如果是其它数据结构呢?这个实现太不灵活。让我们稍稍修改一下,把比较的逻辑抽取出来:
(define (qsort2 l cmp) (if (or (empty? l) (empty? (cdr l))) l (let*-values ([(key) (car l)] [(small big) (partition (lambda (x)(cmp x key)) (cdr l))]) (append (qsort2 small cmp) (list key) (qsort2 big cmp))))) > (qsort2 l <) '(1 2 3 4 5 8 68 74 100 123 234) > (qsort2 l >) '(234 1 2 3 4 5 8 68 74 100 123) > (qsort2 (list "hello" "world" "baby") string<?) '("baby" "hello" "world")
如果你用过Python,一定知道其 sorted 函数可以这样使用:
sorted([(1, "a"), (3, "b"), (2, "c")], key=lambda x: x[0])
[(1, 'a'), (2, 'c'), (3, 'b')]我们自然想让自己的 qsort 有这样的功能了。这也不难,我们需要把 key 的获取抽象出来:
(define (qsort3 l cmp key) (if (or (empty? l) (empty? (cdr l))) l (let*-values ([(item) (car l)] [(small big) (partition (lambda (x) (cmp (key x) (key item))) (cdr l))]) (append (qsort3 small cmp key) (list item) (qsort3 big cmp key))))) > (qsort3 (list '(3 "关上冰箱") '(1 "打开冰箱") '(2 "把大象塞到冰箱里")) < car) '((1 "打开冰箱") (2 "把大象塞到冰箱里") (3 "关上冰箱")) > (qsort3 l < (lambda (x) x)) '(1 2 3 4 5 8 68 74 100 123 234)
现在,功能是丰满了,但函数使用起来越来越麻烦,最初的 (qsort1 l) 变成了如今的 (qsort3 l < (lambda (x) x)),好不啰嗦。还好,Racket提供了函数的可选参数,我们再来修订一下:
(define (qsort l [cmp <] [key (lambda (x) x)]) (if (or (empty? l) (empty? (cdr l))) l (let*-values ([(item) (car l)] [(small big) (partition (lambda (x) (cmp (key x) (key item))) (cdr l))]) (append (qsort small cmp key) (list item) (qsort big cmp key))))) > (qsort l) '(1 2 3 4 5 8 68 74 100 123 234) > (qsort l >) '(234 123 100 74 68 8 5 4 3 2 1)
费了这么多口舌,其实Racket自己就提供了一个全功能的 sort:
> (define l (list 234 123 68 74 100 1 3 5 8 4 2))
> (sort l <) '(1 2 3 4 5 8 68 74 100 123 234)
> (sort (list "hello" "world" "babay") string<?) '("babay" "hello" "world")
> (sort (list '(3 "关上冰箱") '(1 "打开冰箱") '(2 "把大象塞到冰箱里")) #:key car <) '((1 "打开冰箱") (2 "把大象塞到冰箱里") (3 "关上冰箱"))
延伸阅读:更多和 list 相关的函数,可以参考 Pairs and Lists。
2.2.4 vector
vector 是固定长度的数组,vector 和 list 的优缺点可以想象一下C语言中的数组和带尾指针(及长度)的双向链表。我们通过代码先感受一下 vector:
> (define v1 (vector 1 2 3))
> v1 '#(1 2 3)
> (equal? v1 #(1 2 3)) #t
> (vector? v1) #t
> (vector->list v1) '(1 2 3)
> (list->vector '(3 2 1)) '#(3 2 1)
> (vector-ref v1 0) 1
> (for ([i #(1 2 3)]) (display i)) 123
> (vector-take v1 1) '#(1)
> (vector-drop v1 1) '#(2 3)
> (vector-split-at v1 1)
'#(1)
'#(2 3)
> (vector-length v1) 3
> (vector-append v1 #(0 1 2)) '#(1 2 3 0 1 2)
可以看到,vector 的使用几乎和 list 一致,甚至函数的命名都很相似。
延伸阅读:更多和 vector 相关的函数,可以参考 Vectors。
2.2.5 哈希表
哈希表(hash)是目前几乎每种语言都会内置的数据结构。在Python里,它叫 dict;在golang中,它叫 map。哈希表是由一系列键值对(Key-value pair)组成的数据结构,具备和数组相同的 O(1)存取能力(最佳情况)。标准的哈希表的实现方式如下:
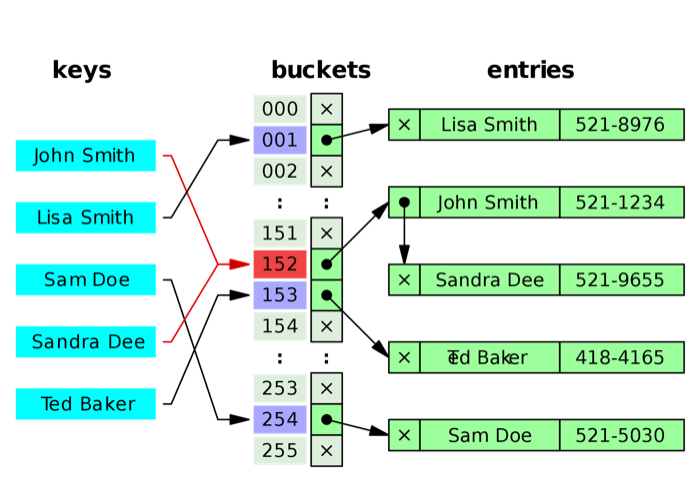
更多有关哈希表的算法和存储方式,请参考:Hash table
当冲突产生时,一般会使用链表来保存冲突链。好的哈希算法会让系统中最长的冲突链尽可能地短。
我们看看Racket中的哈希表如何定义和访问:
> (define ht (hash "key1" "value1" 'key2 1234 3 (list 1 2) (list 'key4) 'value4))
> (hash-ref ht "key1") "value1"
> (hash-ref ht 'key2) 1234
> (hash-ref ht 3) '(1 2)
> (hash-ref ht (list 'key4)) 'value4
> (hash-ref ht 'key5) hash-ref: no value found for key
key: 'key5
哈希表的 key 和 value 可以是任意类型,访问不存在的 key 会抛出异常。通过上面的例子,我们可以看到,哈希表的简写符号是 #hash,key 和 value 间使用 . 来连接。
由于哈希表的 key 可以是任意类型,这就带来一个问题:key 究竟怎么比较?是使用 equal?(相同的值) 还是 eq?(相同的对象),还是 eqv?(字符和数字相同或对象相同)?我们先看看这三种比较方式的区别:
> (eq? (+ 1 1) (+ 1 1)) #t
> (eqv? (+ 1 1) (+ 1 1)) #t
> (equal? (+ 1 1) (+ 1 1)) #t
> (eq? (sqrt 1001) (sqrt 1001)) #f
> (eqv? (sqrt 1001) (sqrt 1001)) #t
> (equal? (sqrt 1001) (sqrt 1001)) #t
> (eq? (list 1 2) (list 1 2)) #f
> (eqv? (list 1 2) (list 1 2)) #f
> (equal? (list 1 2) (list 1 2)) #t
> (eq? (make-string 3 #\z) (make-string 3 #\z)) #f
> (eqv? (make-string 3 #\z) (make-string 3 #\z)) #f
> (equal? (make-string 3 #\z) (make-string 3 #\z)) #t
对应的,哈希表也可以使用 hash,hasheq,hasheqv 来创建,相应的简写符号也不同。不过,通过这三种方式创建的哈希表是不可修改的,可很多使用哈希表的场景都需要修改哈希表,怎么办?Racket提供了 make-hash, make-hasheqv, 以及 make-hasheq。我们看例子:
> (define ht (make-hash))
> (hash-set! ht "key1" 'v1)
> (hash-set! ht (list 1 2) #hash(("k" . "v")))
> (hash-ref (hash-ref ht (list 1 2)) "k") "v"
延伸阅读:更多和 hash 相关的函数,可以参考 Hash Tables。
2.2.6 symbol
在 列表 的例子中,你也许会注意到列表的简写形式:相对于 (list 1 2 3),'(1 2 3) 能更简单地表现一个列表。那么,如果要用它定义嵌套的列表呢?该怎么定义?是 '('(1 2) '(3 4)) 么?让Racket直接告诉我们:
> (list (list 1 2) (list 3 4)) '((1 2) (3 4))
咦!仅需要一个简单的 ’,我们就可以定义嵌套的列表。那么,’究竟是个什么东西?为什么它能够支持列表的嵌套?而不是我们想象的那样去定义?让我们多尝试一些代码,探寻 ’ 的秘密:
> (define l1 ''(1 2 3 4))
> (car l1) 'quote
> (cdr l1) '((1 2 3 4))
> (cadr l1) '(1 2 3 4)
> (caadr l1) 1
> (cdadr l1) '(2 3 4)
> (define l2 '('(1 2) '(3 4)))
> (car l2) ''(1 2)
> (cdr l2) '('(3 4))
> ''1 ''1
> (car ''1) 'quote
> (cdr ''1) '(1)
> (cadr ''1) 1
> (cddr ''1) '()
是不是有中很凌乱的感觉?按照racket的定义,’ 是 quote 的简写,所以 '(1 2 3) 等价于 (quote (1 2 3)),而其会被racket进一步翻译成 (list '1 '2 '3)。在racket里,对数字和字符串 quote 等于其本身:
> '1 1
> '"hello world" "hello world"
> '#t #t
> '#f #f
> 'a 'a
所以 (list '1 '2 '3) 等于 (list 1 2 3)。按这个推演,我们看上面的例子:
> ''(1 2 3 4) -> ''(1 2 3 4) -> (list 'quote '(1 2 3 4)) -> (list 'quote (list 1 2 3 4))
试试看:
> (list 'quote (list 1 2 3 4)) ''(1 2 3 4)
Bingo!我们再看上面那个复杂一些的例子:
> '('(1 2) '(3 4)) -> '('(1 2) '(3 4)) -> (list ''(1 2) ''(3 4)) -> (list (list 'quote '(1 2)) (list 'quote '(3 4))) -> (list (list 'quote (list 1 2)) (list 'quote (list 3 4)))
试试看:
> (list (list 'quote (list 1 2)) (list 'quote (list 3 4))) '('(1 2) '(3 4))
希望你看到这里还没晕。现在你应该理解为什么嵌套的 list 用一个 quote 就能搞定,以及之前例子中 car / cdr 会出来各种凌乱的结果的原因了吧。
好了,热身活动结束,我们谈谈这一节要讲的内容 —— symbol。
在Racket中,使用 ’ quote 起来的符号,就是 symbol。symbol 有点类似于erlang中的atom,是一个不可变的原子值,其值和表现形式一样。symbol 和 variable 不同的地方在于,variable本身是只个符号,其值和符号本身没有任何关系。
> (eq? 'a 'a) #t
从之前的例子中,我们可以看到,一个 quote 会反复作用于内部的表达式,因此一旦一个表达式被 quote 起来,它就不会进行运算:
> '(1 (+ 1 1) 3) '(1 (+ 1 1) 3)
> '(1 (+ 1 1) 3) '(1 (+ 1 1) 3)
> (define x 2)
> '(1 x 3) '(1 x 3)
然而,有些场合下,我们需要内部的表达式计算后再被 quote,成为一个 symbol,怎么办?Racket提供了 quasiquote,标记是 ‘(tab键上边的那个符号)。大部分情况下,quasiquote 和 quote 表现形式是一样的,只有在表达式里出现 unquote(标记是 ,)时,quasiquote 会计算 unquote 的表达式的值:
> '(1 2 3) '(1 2 3)
> `(1 2 3) '(1 2 3)
> '(1 ,(+ 1 1) 3) '(1 ,(+ 1 1) 3)
> `(1 ,(+ 1 1) 3) '(1 2 3)
> `(1 ,(+ 1 1) 3) '(1 2 3)
> '(1 x 3) '(1 x 3)
> `(1 ,x 3) '(1 2 3)
对于Racket来说,代码和数据是没有分别的,这也是Lisp的一大特色。symbol 是代码和数据之间转化的桥梁,在和 syntax 相关的场合会被大量用到,其中 quasiquote 和 unquote 也有很多用武之地。在这一节里,我们可能还无法理解它的作用,但不要紧,之后的章节我们会继续看到它的身影。
延伸阅读:更多和 symbol 相关的函数,可以参考 Symbols。
2.3 撰写模块
2.4 面向对象编程
现在你已经对Racket的主要语法有所掌握,课后作业:阅读Learn X in Y minutes并尝试理解和执行其中涉及到的例子。Good luck!